Texto de Francisco Abundis publicado en Milenio
Consulta Aquí.
Las mediciones electorales están en el centro de la toma de decisiones de todos los partidos políticos. El Frente Amplio por México o la alianza oficialista de Morena, “Juntos hacemos historia”, recurren al mismo método y resuelven sus candidaturas en función de sus resultados. Es irónico escuchar que las encuestas están en crisis. El discurso de la crisis es un lugar común, cuando la toma de decisiones de esos institutos políticos se atiene a sus resultados.
Es preciso distinguir entre los argumentos políticos y los metodológicos cuando entramos en esta discusión, porque la conversación se puede hacer muy confusa. Por ello entender la lógica del método es importante. En sentido estricto lo metodológico es más transparente que la argumentación política. Ello facilita un poco los términos del debate.
En el caso del Frente Amplio, su proceso fue claro, transparente, validable en lo metodológico salvo un par de observaciones. No se alcanza a entender porque hicieron una medición telefónica o hubo una propuesta de hacer mediciones por internet. Parece mucha improvisación, pero sin embargo el método funcionó (la encuesta en vivienda) y hay una ganadora clara: Xóchitl Gálvez.
En el caso de Morena y sus aliados el proceso fue más planeado y diseñado probablemente porque tuvieron más tiempo y fue menos improvisación. Desde hace aproximadamente un año el resultado de la competencia interna del partido en el poder, Morena, era predecible. En el verano de 2022 la entonces jefa de Gobierno, Claudia Sheinbaum, empezó a despegarse del ex Canciller, Marcelo Ebrard. Él estuvo enterado todo el tiempo de esa tendencia y lamentablemente para él, nunca la pudo revertir. Aproximadamente hasta agosto del año pasado la disputa por el liderazgo de la candidatura a la presidencia fue competido, después ya no hubo forma de revertir el resultado, para frustración del ex Canciller. De allí que atacara, vetara y cuestionara todas la mediciones hechas de manera metodológicamente correctas: muestras probabilísticas, cara a cara, en vivienda.
La cantidad de candidatos que estarían en la competencia nunca fue clara. Por ello en Parametria realizamos distintos ejercicios en los que se elegía entre cuatro, tres, o dos candidatos en diferentes combinaciones. En general, entre menos candidatos en la contienda, mayor la diferencia entre ellos. Es decir, más candidatos dispersan más las preferencias, menos candidatos las definen más.
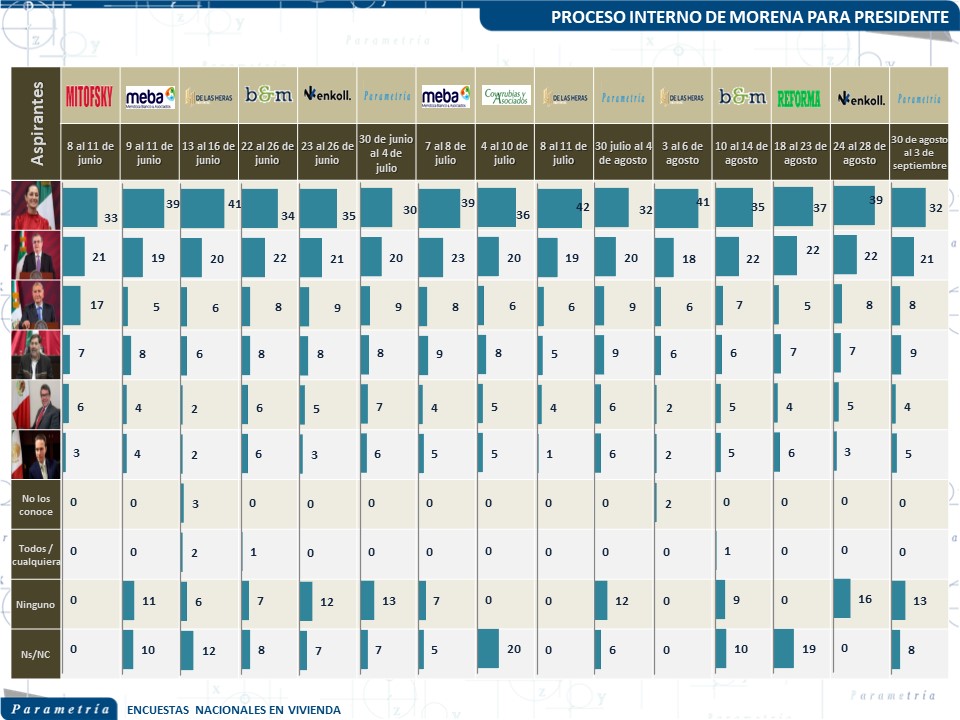
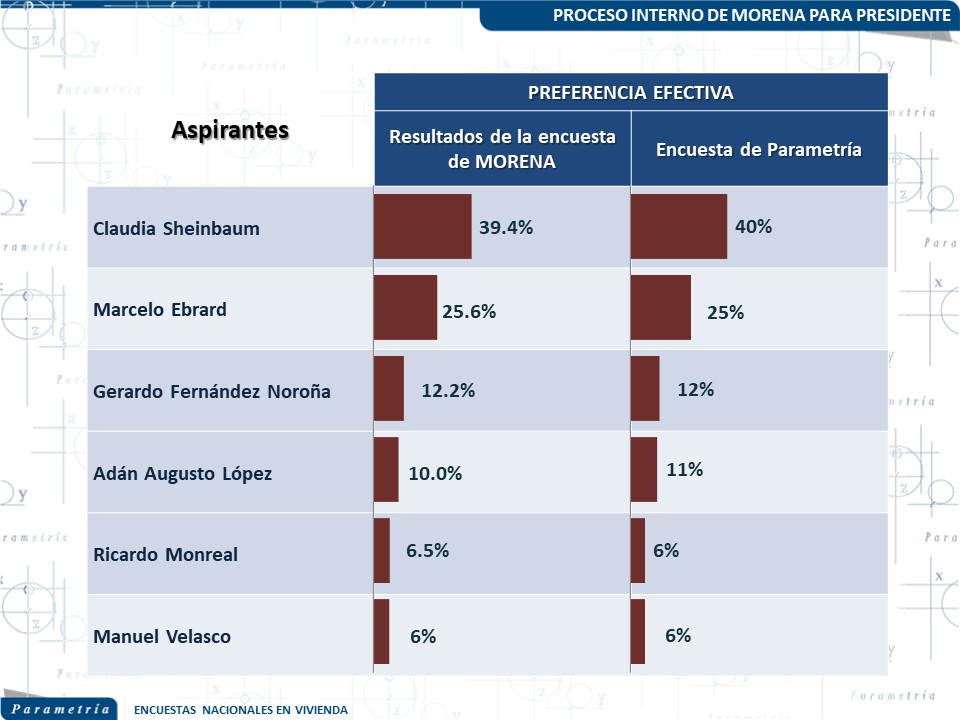
Los resultados que se presentaron el pasado miércoles 6 de septiembre no deberían sorprender a nadie. Todas las mediciones probabilísticas realizadas en vivienda coincidían. La coincidencia de estas mediciones se presta a una reflexión o a algunas preguntas. ¿Por qué las mediciones preelectorales difieren del resultado de la elección? ¿Por qué las mediciones realizadas para este proceso no difirieron tanto entre sí o con las realizadas previamente?
Responder a estas preguntas obliga a hacer una distinción importante. Las mediciones preelectorales miden las preferencias del total del electorado. Los porcentajes de preferencia electoral se corrigen o modela con estimados de participación. Es decir, si no hay diferencia entre las preferencias del 100 por ciento de la población y aquellos que salen a participar la medición preelectoral se parecerá a los resultados de la elección. Si aquellos que participan tienen mayor preferencia por un candidato o alguna fuerza electoral se van a observar diferencias. Si en México tuviéramos voto obligatorio como sucede en algunos casos de América Latina las diferencias entr mediciones preelectorales y resultado electoral, serían más similares.
Los que observamos el miércoles 6 de septiembre pasado fueron mediciones del 100 por ciento del electorado. Si bien hubo una medición “oficial”, “institucional”, “madre” o como se le haya denominado, esta no estuvo corregida por participación. El resto de las cuatro mediciones también contemplaron al 100 por ciento del electorado, de allí su similitud. Y si este argumento lo extendemos a lo publicado antes de este proceso o medición de encuestas observamos el mismo fenómeno: las mediciones no difieren mucho.
La crítica parece estar muy atenta en los casos en los que las mediciones difieren, pero parece no importarles mucho porque en algunos casos coinciden. Las mediciones del pasado miércoles fueron sorprendentemente coincidentes. No debe sorprender este resultado ya que cada medición tuvo el mismo diseño muestral, los mismos ponderadores, el mismo cuestionario, las mismas boletas: Fueron como bien se anunció, mediciones espejo.
Las irregularidades que citó uno de los candidatos no son sustantivas o tiene que ver con temas técnicos o de metodología. No hubo cuestionamientos sustanciales. Todas las observaciones tenían que ver con la falta de cumplimiento de requisitos de seguridad o faltas en mecanismos basados en la desconfianza. Si esas faltas hubieran sido sistemáticas los resultados de los cinco ejercicios realizados no habrían coincidido.
Sin duda el ejercicio es perfectible pero para estar en medio y resolver una decisión de orden eminentemente político parece haber cumplido con su función. En nuestro país hemos tenido ejercicios similares a nivel local o tomar decisiones dentro de un partido, pero tal vez nunca con la contundencia y visibilidad que tuvo este instrumento.
Es interesante que se hable de una crisis de credibilidad en las encuestas, ahora que están precisamente en el centro de la toma de decisiones. Creo que muchos de los analistas siguen sin distinguir entre la publicidad disfrazada de investigación, de la investigación y sus límites.